



OpenAI, one of the entities that is making the most advances in the field of artificial intelligence right now, has two new AIs or neural networks — DALL-E and CLIP.
OpenAI has announced the creation of these two multimodal AI systems, DALL-E and CLIP, cable to find associations between visual and textual concepts from billions of GPT-3 parameters.
DALL-E is capable of generating images from a text description and CLIP, an artificial intelligence capable of visually recognizing images and instantly categorizing them. Both neural networks take advantage of the power of GPT-3, the OpenAI language model presented during 2020.
DALL-E
The purpose of DALL-E is none other than to generate images from scratch based on a given description. According to OpenAI, it uses a 12 billion parameter version of GPT-3 for this. This allows the AI system to create different versions of images based on what is asked of by the user with astonishing precision on many occasions.
Check out how DALL-E’s outcome for the query, “a pentagonal green clock.” or “a green clock in the shape of a pentagon.”


CLIP
CLIP (Contrastive Language–Image Pre-training), for its part is designed to carry out an almost opposite process. Thanks to having been trained with 400 million parts of images and text from the Internet, it is able to instantly recognize which category the images shown to it belong to . The system recognizes objects, characters, locations, activities, subjects, and more.

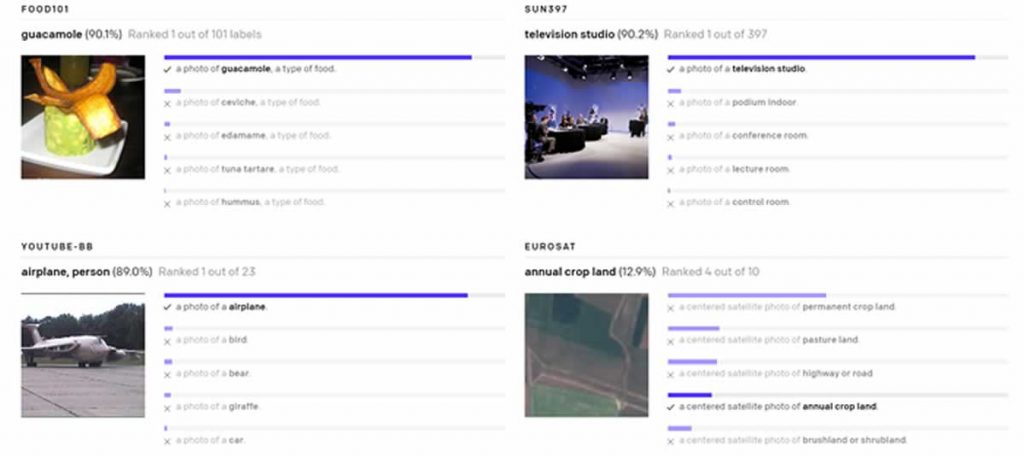
With this, the CLIP can be given an image to describe it in the best possible way. The AI returns a series of descriptions indicating how much of it is sure of it.
While CLIP usually performs well on recognizing common objects, it struggles on more abstract or systematic tasks such as counting the number of objects in an image and on more complex tasks such as predicting how close the nearest car is in a photo.
{kind=link}