



Researchers from Microsoft Azure Cognitive Service Research and the UNC NLP (Natural Language Processing) team have unveiled a cutting-edge generative model called CoDi. This groundbreaking development brings state-of-the-art capabilities to seamlessly generate high-quality content across multiple modalities, paving the way for a more holistic understanding of the world and transforming the nature of human-computer interaction.
The research paper introduces CoDi as an innovative generative model capable of processing and simultaneously generating content across different modalities such as text, image, video, and audio. This distinguishes CoDi from traditional generative AI systems that are limited to specific input modalities.
The architecture of CoDi leverages an alignment strategy to match modalities in both input and output spaces, mitigating the challenge of limited training datasets for most modality combinations. Consequently, CoDi can be conditioned on any combination of inputs and generate any set of modalities, including those not present in the training data.
One notable area where CoDi can potentially drive transformation is in assistive technologies that empower people with disabilities to interact more effectively with computers. By seamlessly generating text, image, video, and audio content, CoDi can offer users a more immersive and accessible computing experience.
Furthermore, CoDi can reinvent custom learning tools by providing a comprehensive and interactive learning environment. Students can deepen their understanding and engagement with the subject matter by engaging with multimodal content that seamlessly integrates information from diverse sources.
CoDi also addresses the limitations of traditional single-modality AI models by offering a solution to the often tedious and time-consuming process of combining modality-specific generative models. Its composable generation strategy bridges alignment in the diffusion process and facilitates the synchronized generation of intertwined modalities, such as temporally aligned video and audio.
The training process of CoDi involves projecting input modalities, including images, video, speech, and language, into a common semantic space. This unique approach enables the model to generate coherent and synchronized multimodal output.
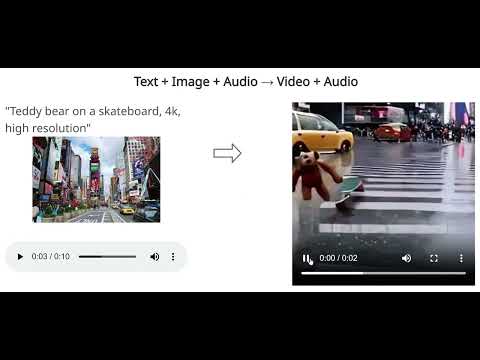
To showcase the capabilities of CoDi, researchers provided an example where the model generated synchronized video and audio from separate text, audio, and image prompts. For instance, the input included the text prompt “teddy bear on skateboard, 4k, high resolution,” an image of Times Square, and the sound of rain. CoDi successfully generated a short video of a teddy bear skateboarding in the rain in Times Square, synchronizing the sound of rain with street noise.
The potential applications of CoDi are vast. It has the potential to revolutionize content creation by streamlining the process and easing the burden on creators. Whether it’s generating engaging social media posts, creating interactive multimedia presentations, or crafting compelling storytelling experiences, CoDi’s capabilities can reshape the landscape of content generation.
{kind=link}