
Microsoft has released a new research paper emphasizing the significance of combining language, behaviour, multimodal perception, and world modelling to create artificial general intelligence (AGI).
The study “Language Is Not All You Need: Aligning Perception with Language Models” introduces KOSMOS-1, a multimodal large-scale language model (MLLM).
Microsoft tested the KOSMOS-1 model on various languages and visual tasks, including language comprehension, language generation, picture captioning, visual question answering, and more. According to the evaluation findings, KOSMOS-1 outperformed all of these tasks.

The researchers underlined the necessity of multimodal perception in reaching AGI. Multimodal perception entails both information acquisition and anchoring in reality. It is an essential component of intelligence that must be incorporated into language models to achieve AGI.
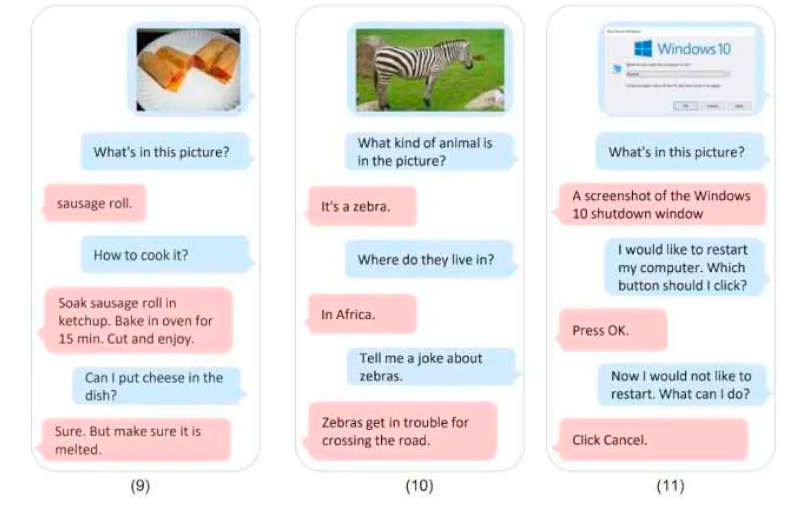
Microsoft trained Kosmos-1 with web data, such as extracts from The Pile (an 800GB English text collection) and Common Crawl. To train the language aspect of the model, Microsoft likely used a large corpus of text data, such as books, articles, and web pages. The model was trained to understand and generate natural language using various techniques, such as neural networks and transformers.
To train the visual aspect of the model, Microsoft likely used large images and video datasets, such as ImageNet and COCO. Using computer vision techniques, such as convolutional neural networks, the model was trained to recognize objects, scenes, and other visual features.
The training process likely involved iterative refinement of the model’s architecture and parameters to optimize its performance on various tasks. The KOSMOS-1 model from Microsoft is a step in the right direction towards AGI.
In the future, the researchers intend to expand the model size of KOSMOS-1 and incorporate voice features into the model. These advancements will result in significantly higher performance and more advanced AGI capabilities.
Finally, Microsoft’s research study combines language, behaviour, multimodal perception, and world modelling to accomplish AGI. The KOSMOS-1 model is a potential advancement, outperforming other models in several language and visual tasks. As technology advances, we may anticipate ever more complex AGI models.
{kind=link}