
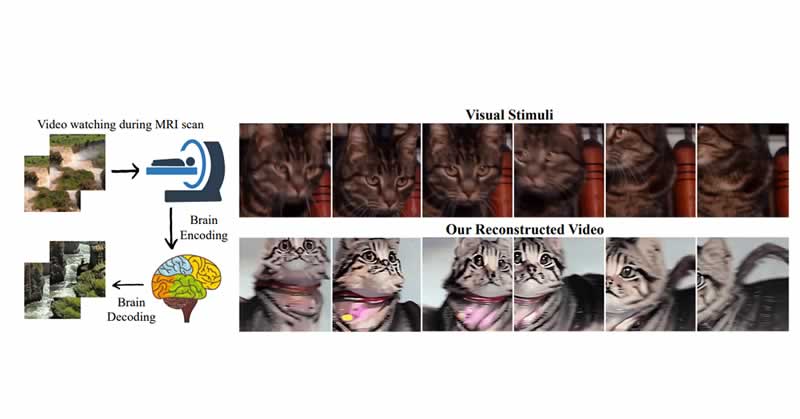
A groundbreaking research study jointly by the National University of Singapore and the Chinese University of Hong Kong has successfully reconstructed “high-quality” videos using artificial intelligence to process signals from human brain activity.
The study utilized popular AI model that generates images from text, Stable Diffusion, and a model that generates videos from brain waves called MinD-Video.
The MinD-Video system, defined as a “two-module pipeline,” was particularly designed to bridge the gap between image and video brain decoding. To train the system, researchers utilized a publicly available dataset containing videos and functional magnetic resonance imaging (fMRI) and electroencephalogram (EEG) readings of subjects who watched those videos.
The study’s findings revealed a remarkable level of similarity between the videos shown to subjects and the videos generated by the AI model based on their brain activity. This suggests that the AI system was able to accurately interpret and reconstruct visual information based on the neural signals captured by fMRI and EEG.
The researchers emphasize that this technique holds immense promise for various fields, ranging from neuroscience to brain-computer interfaces, particularly as large-scale models continue to be developed.
The study’s results also shed light on three significant discoveries. Firstly, the predominance of the visual cortex indicates that this region plays a crucial role in visual perception. Additionally, the fMRI encoders operate hierarchically, with the initial layers capturing structural information and deeper layers focusing on more abstract and visual features. Lastly, the fMRI encoder evolves and improves with each learning stage, demonstrating its ability to capture increasingly nuanced information as training progresses.
This study represents a significant advancement in using AI to decipher human thoughts. Previous research by scientists at Osaka University had already demonstrated the reconstruction of high-resolution images from brain activity using fMRI data and stable diffusion techniques.
Building upon this prior work, the researchers extended the Stable Diffusion model to enhance the accuracy of visualization. In their paper, they highlight one of the key advantages of the stable diffusion model over other generative models, such as generative adversarial networks (GANs): its ability to generate videos of not only superior quality but also more consistent with the original neural activity.
The successful reconstruction of high-quality videos from human brain activity opens up a wide range of potential applications and implications. It offers a glimpse into the remarkable capabilities of AI in understanding and interpreting neural signals, which could lead to advancements in fields such as neuroscience, brain-computer interfaces, and even multimedia production.
{kind=link}