
Mistral AI has announced the release of Mixtral 8x7B, a state-of-the-art sparse mixture of experts (SMoE) model.
Mixtral 8x7B, accessible via a magnet link, is a high-quality SMoE model that demonstrates exceptional performance in language generation, code generation, and instruction following. It represents a significant step forward from its previous model, Mistral-7B-v0.1.
Its architecture, which utilizes multiple specialized submodels or “experts,” allows for a more efficient processing of tasks. An input token is processed by a router network that selects only a few relevant experts, enabling the model to use only 12 billion of its 45 billion total parameters per token. This unique design combines the depth of a large-scale neural network with the efficiency of a smaller model.
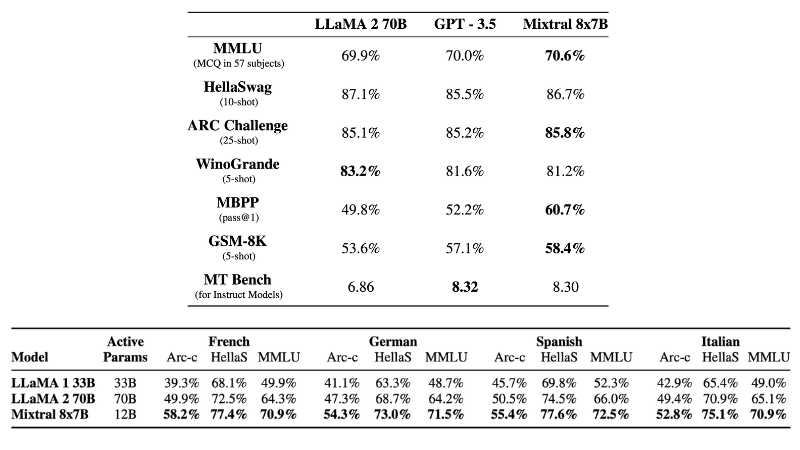
In terms of performance, Mixtral 8x7B matches or exceeds other leading open models like Llama 2 70B and GPT-3.5 Base. It shines in handling long contexts up to 32k tokens and achieves top scores in instruction following, with a notable 8.3 on MT-Bench. Additionally, Mixtral 8x7B displays higher truthfulness and less bias compared to its counterparts, making it a more reliable choice in AI modeling.
Alongside the standard model, Mistral AI has also released Mixtral 8x7B Instruct, optimized for precise instruction following. This variant, enhanced through supervised fine-tuning and Direct Preference Optimization (DPO), competes closely with models like GPT-3.5, further cementing its position as a leading open-source model.
One of the most notable features of Mixtral 8x7B is its multilingual capability. The model is adept in English, French, Italian, German, and Spanish, making it a versatile tool for global applications. Licensed under the permissive Apache 2.0 license, Mixtral 8x7B is set to democratize access to advanced AI technologies.
Mistral AI has made it possible for users to experience Mixtral 8x7B firsthand through various demos available on platforms like Perplexity Labs Playground, Poe, Vercel, and Replicate. These demos provide a practical understanding of the model’s capabilities in real-world scenarios.
{kind=link}