
Apple has unveiled MM1, its first-ever multimodal AI model, poised to enhance how Siri and iMessage understand and interact with both images and text.
MM1, representing a new family of multimodal models by Apple, is designed to process and interpret both images and text, boasting up to 30 billion parameters. This makes it competitive with Google’s initial versions of Gemini, showcasing its ability to follow instructions and reason across different forms of media. For example, MM1 can accurately determine the cost of two beers from an image of a menu, illustrating its sophisticated multimodal abilities.

At its core, MM1 features a hybrid encoder that processes both visual and textual data, enhancing its ability to generate and understand integrated content. The vision-language connector serves as a crucial component, merging the model’s capabilities in image processing and text understanding. This integration allows for a seamless operation between visual and linguistic elements. MM1’s design also emphasizes scalability and efficiency, employing a mix of traditional dense models and mixture-of-experts (MoE) variants to increase capacity without overburdening computational resources.
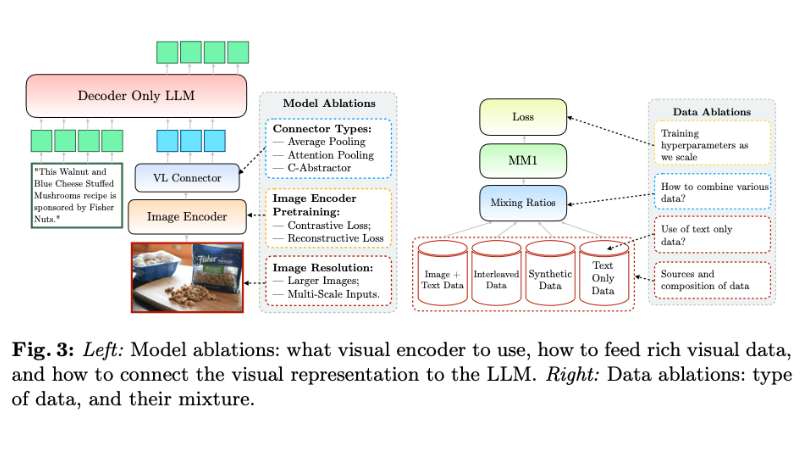
A standout feature of MM1 is its in-context learning capability, allowing the model to understand and respond to queries based on the context of the current conversation. This eliminates the need for constant retraining or fine-tuning for new types of queries or tasks. Additionally, MM1’s multi-image reasoning enables it to comprehend, interpret, and derive conclusions from multiple images within the same query, thus facilitating more complex and nuanced interactions with visual content.
The integration of MM1’s multimodal understanding capabilities could significantly improve Apple’s voice assistant, Siri, and its messaging platform, iMessage. Siri could be empowered to answer questions using visual context, while iMessage could better understand the context of shared images and texts, providing users with more relevant response suggestions.
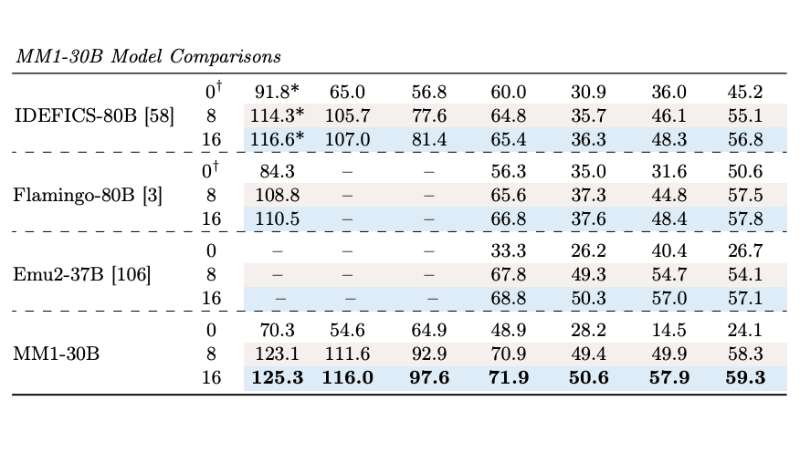
Apple’s MM1 also excels in performance, surpassing existing models like Flamingo and IDEFICS, which are more than double its size. The research underpinning MM1 revealed that a balanced mix of image-caption, interleaved image-text, and text-only data was essential to achieve state-of-the-art performance in large-scale multimodal pre-training.
Apple has lagged behind in terms of AI innovation compared with OpenAI, Google, and Microsoft. With rumoured web application-based chatbot service, Apple GPT, remaining under wraps, the company’s recent release of the MGIE and MLX toolkit and acquisition of Canadian AI startup DarwinAI give a significant boost to the tech giant in AI community.
{kind=link}